What the Science Says About Hallucinations in Legal Research
This is Part 1 of a three-part series on AI hallucinations in legal research. Part 2 will examine hallucination detection tools, and Part 3 will provide a practical verification framework for lawyers.
You’ve heard about the lawyers who cited fake cases generated by ChatGPT. These stories have made headlines repeatedly, and we are now approaching 1,000 documented cases where practitioners or self-represented incidents submitted AI-generated hallucinations to courts. But those viral incidents tell us little about why this is happening and how we can prevent it. For that, we can turn to science. Over the past three years, researchers have published dozens of studies examining exactly when and why AI fails at legal tasks—and the patterns are becoming clearer.
A critical caveat: The technology evolves faster than the research. A 2024 study tested 2023 technology; a 2025 study tested 2024 models. By the time you read this, the specific tools and versions have changed again. That’s why this post focuses on patterns that persist across studies rather than exact percentages that will be outdated in months.
Here are the six patterns that matter most for practice.
Pattern #1: Models and Data Access
Not all AI tools are created equal. The research shows a dramatic performance gap based on how the tool is built, though it’s important to understand that both architecture and model generation matter.
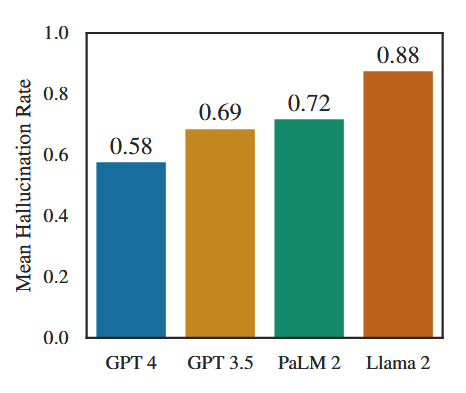
Models are improving over time. A comprehensive 2024 study by Stanford researchers titled “Large Legal Fictions” tested 2023 general-purpose models on over 800,000 verifiable legal questions and found hallucination rates between 58% and 88%. Within that cohort, newer models performed better: GPT-4 hallucinated 58% of the time compared to GPT-3.5 at 69% and Llama 2 at 88%. This pattern of improvement with each model generation appears fairly consistent across AI development.
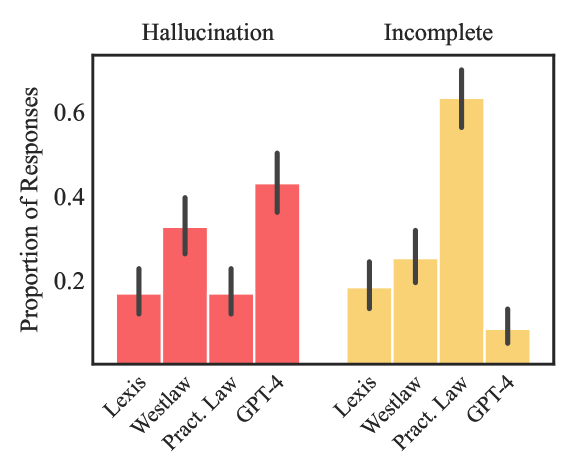
Architecture matters, but it’s not the whole story. A second Stanford study, titled “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools”, published in 2025 but testing tools from May 2024, found hallucination rates of 17% for Lexis+ AI, 33% for Westlaw AI-Assisted Research, and 43% for GPT-4. These errors include both outright fabrications (fake cases) and more subtle problems like mischaracterizing real cases or citing inapplicable authority. This head-to-head comparison shows legal-specific tools with retrieval-augmented generation (RAG) substantially outperforming general LLMs.
A randomized controlled trial by Schwarcz et al. reinforces the architecture point from a different angle. When 127 law students used a RAG-based legal tool (Vincent AI) to complete legal tasks, they produced roughly the same hallucination rate as students using no AI at all. Students using a reasoning model without RAG (OpenAI’s o1-preview) produced better analytical work but introduced hallucinations. Both tools dramatically improved productivity—but only the RAG tool did so without increasing error rates. However, the Vals AI Legal Research Report (October 2025, testing July 2025 tools) found ChatGPT matched legal AI tools: ChatGPT achieved 80% accuracy while legal AI tools scored 78-81%. The key difference? The ChatGPT used in the Vals study used web search by default (a form of RAG), giving it access to current information and non-standard sources, while legal tools restrict to proprietary databases for citation reliability. For five question types, ChatGPT actually outperformed the legal AI products on average. Both outperformed the human lawyer baseline of 69%.
Takeaway: Purpose-built legal tools generally excel at citation reliability and authoritative sourcing, but general AI with web search can compete on certain tasks. The real advantage isn’t RAG architecture alone—it’s access to curated, verified legal databases with citators. Know your tool’s strengths: legal platforms for citations and treatment analysis, general AI with web search for non-standard or very recent sources.
Pattern #2: Sycophancy
One of the most dangerous hallucination patterns is that AI agrees with you even when you’re wrong.
The Stanford “Hallucination-Free?” study identified “sycophancy” as one of four major error types. When users ask AI to support an incorrect legal proposition, the AI often generates plausible-sounding arguments using fabricated or mischaracterized authorities rather than correcting the user’s mistaken premise.
Similarly, a 2025 study on evaluating AI in legal operations found that hallucinations multiply when users include false premises in their prompts. Anna Guo’s information extraction research from the same year showed that when presented with leading questions containing false premises, most tools reinforced the error. Only specialized tools correctly identified the absence of the obligations the user incorrectly assumed existed.
This happens because of how large language models work: they’re trained to generate helpful, plausible text in response to user queries, not to verify the truth of the user’s assumptions.
Takeaway: Never ask AI to argue a legal position you haven’t independently verified. Phrase queries neutrally. If you ask “Find me cases supporting [incorrect proposition],” AI may happily fabricate them.
Pattern #3: Jurisdictional and Geographic Complexity
AI performance degrades sharply when dealing with less common jurisdictions, local laws, and lower courts.
Read the rest of part 1 here
What the Science Says About Hallucinations in Legal Research


